| CPC G06F 16/285 (2019.01) [G06F 16/288 (2019.01); G06F 16/353 (2019.01); G06F 16/93 (2019.01); G06F 16/951 (2019.01)] | 17 Claims |
|
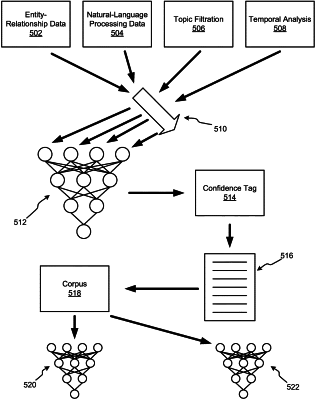
1. A method comprising:
obtaining a document of written content, wherein the document is a candidate for inclusion in a corpus;
identifying a first entity associated with the document;
identifying a first discrete entity associated with the first entity;
analyzing a relationship between the first entity and the first discrete entity, wherein the analyzing comprises vectorizing entity-relationship information related to the first entity and processing the vectorized information in a neural network;
determining, based on the analyzing, a likelihood that the document contains content that would be detrimental for inclusion in the corpus; and
rejecting, based on the analyzing and the likelihood, the document from the corpus.
|