| CPC G06F 9/5027 (2013.01) [G06F 9/3455 (2013.01); G06F 9/3851 (2013.01); G06F 9/3877 (2013.01); G06F 9/3885 (2013.01); G06F 9/4881 (2013.01); G06F 9/5033 (2013.01); G06F 9/5066 (2013.01); G06F 9/545 (2013.01); G06F 12/0837 (2013.01); G06F 9/30178 (2013.01); G06F 9/3887 (2013.01); G06F 16/24569 (2019.01); G06T 1/20 (2013.01); G06T 1/60 (2013.01); G06T 15/005 (2013.01)] | 20 Claims |
|
1. An apparatus comprising:
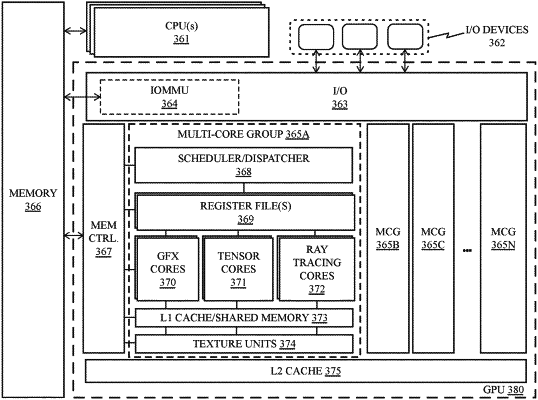
a plurality of processors including a plurality of graphics processors to process data, the graphics processors including a set of tensor cores, wherein the plurality of processors are to schedule threads for a plurality of tensor operations for processing by the plurality of tensor cores;
a memory; and
one or more caches for storage of data for the plurality of graphics processors, the one or more caches including storage of data for the tensor operations scheduled for processing by the plurality of processors;
wherein the one or more caches utilize a cache locality in which spatial locality of caching of data within the one or more caches is based at least in part on relationships in thread assignment; and
wherein the scheduling of the threads by the plurality of processors includes applying a bias for assigning threads to tensor cores according to the cache locality utilized for the one or more caches.
|