| CPC H04L 43/065 (2013.01) [H04L 41/0627 (2013.01); H04L 41/12 (2013.01); H04L 43/0817 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
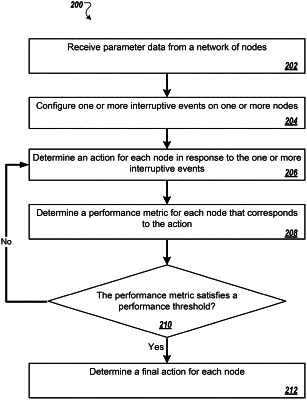
receiving, at one or more computing devices, parameter data from a network of nodes, the parameter data comprising attributes, policies, and action spaces for each node included in the network of nodes;
configuring, by the one or more computing devices, one or more interruptive events on one or more nodes included in the network of nodes;
determining, by the one or more computing devices, a first action of each node included in the network of nodes in response to the one or more interruptive events;
determining, by the one or more computing devices, a first performance metric, for each node, that corresponds to the first action, wherein the first performance metric is determined based on at least a first reward value associated with the first action;
performing a reinforcement learning process to train a machine learning model to generate actions to be performed by nodes that improve anti-fragility of the network, including continuously updating, by the one or more computing devices, the first action for each node in the reinforcement learning process until an anti-fragility metric of a final action satisfies a performance threshold representing the anti-fragility of the network, wherein updating the first action for a node in the reinforcement learning process comprises:
determining an updated action for the node based on the first performance metric of the first action, and
determining an updated performance metric, for the node, that corresponds to the updated action, wherein the updated performance metric is determined based on an updated reward value associated with the updated action, and wherein the updated reward value is larger than the first reward value; and
transmitting, by the one or more computing devices, the final action for each node to the network of nodes, whereby each node performs the final action in response to the one or more interruptive events.
|