| CPC G10L 13/047 (2013.01) [G10L 15/063 (2013.01); G10L 2015/0635 (2013.01)] | 19 Claims |
|
1. A client device comprising:
at least one microphone;
at least one display;
local storage storing a textual segment, an end-to-end speech recognition model, and a speech synthesis model;
one or more processors executing locally stored instructions to cause one or more of the processors to:
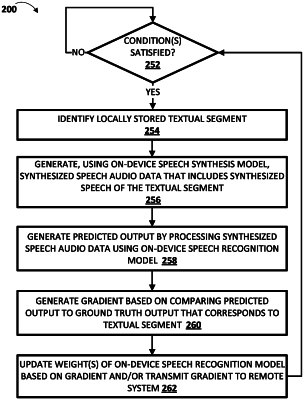
identify the textual segment;
generate synthesized speech audio data that includes synthesized speech of the identified textual segment, wherein in generating the synthesized speech audio data one or more of the processors are to process the textual segment using the speech synthesis model;
process, using the end-to-end speech recognition model, the synthesized speech audio data to generate a predicted textual segment;
generate a gradient based on comparing the predicted textual segment to the textual segment; and
update one or more weights of the end-to-end speech recognition model based on the generated gradient.
|