| CPC G06T 11/001 (2013.01) [G06T 7/90 (2017.01); G06T 2207/20081 (2013.01)] | 20 Claims |
|
1. A computing system configured to perform view synthesis, the computing system comprising:
one or more processors;
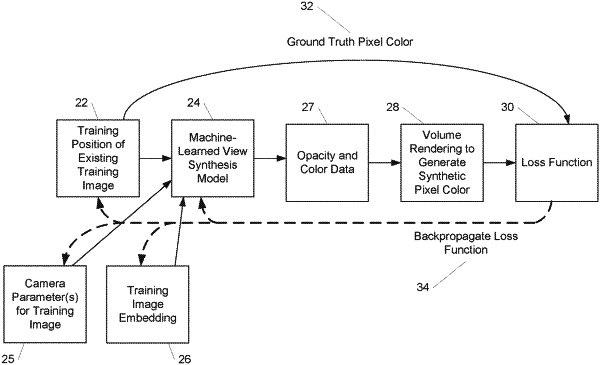
a machine-learned view synthesis model configured to receive and process a position of a desired synthetic image to generate a synthetic image of a scene from the position,
wherein the machine-learned view synthesis model comprises a neural radiance field model,
wherein the machine-learned view synthesis model comprises a static content portion that models static content within the scene and a transient content portion that models transient occluders within the scene,
wherein the neural radiance field model has been trained on a set of training images that depict the scene, and
wherein the set of training images comprise unconstrained images that include the transient occluders; and
one or more non-transitory computer-readable media that collectively store instructions that, when executed by the one or more processors, cause the computing system to perform operations, the operations comprising:
obtaining the position of the desired synthetic image;
processing the position of the desired synthetic image with the machine-learned view synthesis model to generate the synthetic image; and
providing the synthetic image as an output.
|