| CPC G06N 20/20 (2019.01) [G06F 40/126 (2020.01); G06F 40/284 (2020.01)] | 18 Claims |
|
1. A method for providing a variety of natural language processing (NLP) models during runtime, comprising:
receiving a first input data comprising a first input text and a first task type, the first task type specifying one or more target NLP task types to be performed on the first input text;
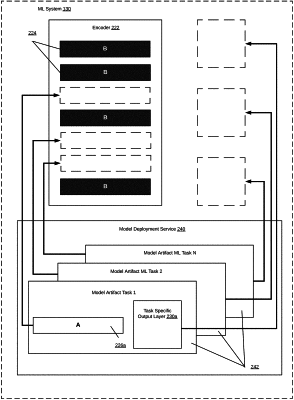
dynamically generating a first model tuned to generate predictions for a first NLP task having the first task type, the generating comprising integrating, into a base model during runtime, a first model artifact comprising one or more adapter layers specific to the first task type;
generating, during the same runtime and based on processing the first input text with the first model generated during the same runtime, a prediction for the first NLP task;
providing the prediction to one or more application instances,
receiving a second input data comprising a second input text and a second task type, the second task type specifying one or more target NLP task types to be performed on the second input text, wherein the second task type is different from the first task type;
generating, during the same runtime, a second model tuned to generate predictions for a second NLP task having the second task type, the generating comprising dynamically exchanging the first model artifact with a second model artifact comprising one or more adapter layers specific to the second task type;
generating, during the same runtime, a second prediction for the second NLP task by processing the second input text using the second model; and
distributing the second prediction to the one or more application instances.
|