| CPC G06N 20/00 (2019.01) [G06F 16/2264 (2019.01); G06F 16/285 (2019.01)] | 20 Claims |
|
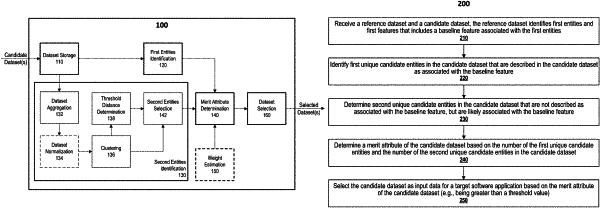
1. A method for applying machine-learning techniques to evaluate candidate datasets for use by software applications, the method comprising performing, by one or more processing devices, operations including:
identifying, in a candidate dataset identifying first entities associated with first features, first unique candidate entities that are absent from a reference dataset identifying second entities associated with second features that include a baseline feature of a target population and that are associated with the baseline feature in the candidate dataset;
forming, in a multi-dimensional space and based on a subset of the second features lacking the baseline feature, a cluster of data points representing the second entities;
mapping a subset of the first entities that are absent from the reference dataset and that are not in the first unique candidate entities to additional data points, respectively in the multi-dimensional space;
identifying, from the subset of the first entities, second unique candidate entities corresponding to a subset of the additional data points within a threshold distance of the cluster;
determining a merit attribute of the candidate dataset based on a first weight for each first unique candidate entity, a second weight for each second unique candidate entity, a number of the first unique candidate entities in the candidate dataset, and a number of the second unique candidate entities in the candidate dataset; and
selecting the candidate dataset as input data for a target software application based on the merit attribute of the candidate dataset being greater than a threshold value.
|