| CPC G06N 3/08 (2013.01) [G06N 20/00 (2019.01); G06N 20/10 (2019.01)] | 20 Claims |
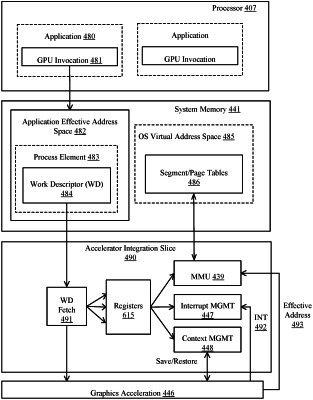
|
1. An apparatus comprising:
a general purpose graphics processing unit (GPGPU) comprising a plurality of streaming multiprocessors (SMs), the GPGPU to:
receive a plurality of data inputs for training a neural network executed by the plurality of SMs, wherein the data inputs comprise training data and weights inputs;
perform measurements of compute power and latency of the plurality of SMs;
determine a ratio of the compute power for the plurality of SMs; and
assign, in accordance with the ratio of the compute power and in accordance with the latency, the training data in a low precision form and the weight inputs in a high precision form among the plurality of SMs, wherein the low precision form is lower than the high precision form.
|