| CPC G06F 40/30 (2020.01) [G06F 18/214 (2023.01); G06F 40/44 (2020.01); G06F 40/49 (2020.01); G06F 40/51 (2020.01)] | 9 Claims |
|
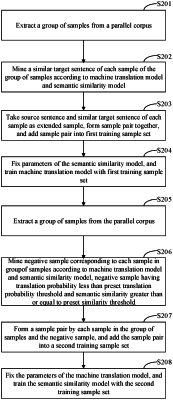
1. A method for training models in machine translation, comprising:
mining similar target sentences of a group of samples based on a parallel corpus using a machine translation model and a semantic similarity model, and creating a first training sample set;
training the machine translation model with the first training sample set;
mining a negative sample of each sample in the group of samples based on the parallel corpus using the machine translation model and the semantic similarity model, and creating a second training sample set; and
training the semantic similarity model with the second training sample set,
wherein the mining a negative sample of each sample in the group of samples based on the parallel corpus using the machine translation model and the semantic similarity model, and creating a second training sample set, comprises:
extracting a group of samples from the parallel corpus;
mining a negative sample corresponding to each sample in the group of samples according to the machine translation model and the semantic similarity model, the negative sample having a translation probability less than a preset translation probability threshold and a semantic similarity greater than or equal to a preset similarity threshold; and
forming a sample pair by each sample in the group of samples and the negative sample, and adding the sample pair into the second training sample set,
wherein the mining a negative sample corresponding to each sample in the group of samples according to the machine translation model and the semantic similarity model, the negative sample having a translation probability less than a preset translation probability threshold and a semantic similarity greater than or equal to a preset similarity threshold, comprises:
acquiring a target sentence and a plurality of candidate target sentences in each sample of the group of samples as well as the translation probability of each candidate target sentence according to the machine translation model, wherein the target sentence, the candidate target sentences and the translation probabilities are obtained after the machine translation model translates a source sentence in the sample;
screening a plurality of alternative target sentences having the translation probabilities less than the preset translation probability threshold from the plurality of candidate target sentences according to the translation probability of each candidate target sentence;
calculating the semantic similarities of the source sentence and each alternative target sentence using the semantic similarity model respectively; and
acquiring the alternative target sentence having the semantic similarity greater than or equal to the preset similarity threshold from the plurality of alternative target sentences to serve as the target sentence of the negative sample, and forming the negative sample together with the source sentence of the sample.
|