| CPC G06F 16/24578 (2019.01) [G06F 16/285 (2019.01); G06F 16/35 (2019.01); G06F 16/9535 (2019.01); G06F 18/23 (2023.01)] | 20 Claims |
|
1. A method comprising:
obtaining a first plurality of records, wherein each record of the first plurality of records is associated with a respective entity and comprises a first one or more fields;
obtaining a second plurality of records, wherein each record of the second plurality of records is associated with a respective entity and comprises a second one or more fields;
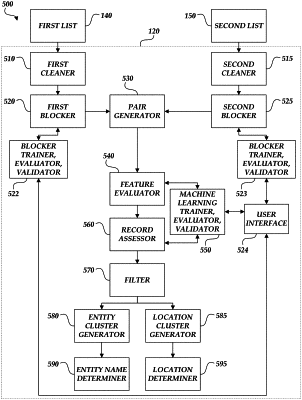
generating a plurality of record pairs, wherein each record pair in the plurality of record pairs comprises a respective first record from the first plurality of records and a respective second record from the second plurality of records, and wherein at least one field of the first record differs from a corresponding field of the second record;
applying a blocking model to the plurality of record pairs to generate a plurality of groups of record pairs, wherein the blocking model generates individual groups of record pairs based at least in part on relationships between individual fields of the first one or more fields and individual fields of the second one or more fields;
causing a client computing device to present at least a portion of the plurality of groups of record pairs to a user;
receiving, from the client computing device, user feedback identifying one or more bad groups of record pairs;
retraining the blocking model and generating an updated plurality of groups of record pairs based at least in part on the user feedback;
identifying, based at least in part on the updated plurality of groups of record pairs, a respective cluster of record pairs for each record in the first plurality of records, wherein each record pair in the cluster includes the record;
determining, based at least in part on one or more criteria for evaluating clusters, that each cluster of record pairs corresponds to a respective entity;
identifying, for each cluster of record pairs, a respective record in the second plurality of records based at least in part on the record pairs in the cluster; and
outputting the clusters of record pairs and the respective record in the second plurality of records to the client computing device.
|