| CPC G06F 16/2282 (2019.01) [G06F 16/215 (2019.01); G06F 16/28 (2019.01)] | 20 Claims |
|
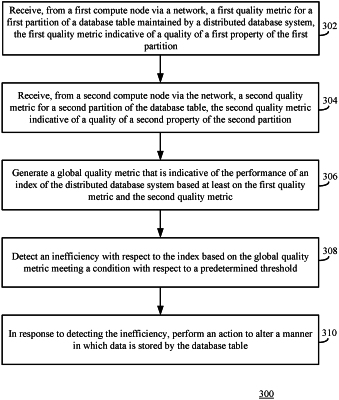
1. A method, comprising:
receiving, from a first compute node via a network, a first quality metric for a first partition of a database table maintained by a distributed database system, the first quality metric-comprising a first data clustering quality metric that is based at least on a first overlap value that indicates a maximum number of data files of the first partition that include a row having a particular value of a particular clustering key of first multiple clustering keys;
receiving, from a second compute node via the network, a second quality metric for a second partition of the database table, the second quality metric comprising a second data clustering quality metric that is based at least on a second overlap value that indicates a maximum number of data files of the second partition that include a row having a particular value for a particular clustering key of second multiple clustering keys;
determining a greatest data clustering quality metric from among at least the first data clustering quality metric and the second data clustering quality metric;
in response to determining that the first data clustering quality metric is the greatest data clustering quality metric, designating the first data clustering quality metric as a global data clustering quality metric that is indicative of the performance of an index of the distributed database system;
in response to determining that the second data clustering quality metric is the greatest data clustering quality metric, designating the second data clustering quality metric as the global data clustering quality metric;
detecting an inefficiency with respect to the index based on the global data clustering quality metric meeting a condition with respect to a predetermined threshold; and
in response to detecting the inefficiency, performing an action to alter a manner in which data is stored by the database table.
|