| CPC G10L 17/18 (2013.01) [G06N 3/045 (2023.01); G06N 3/08 (2013.01); G10L 15/07 (2013.01); G10L 15/20 (2013.01); G10L 17/04 (2013.01)] | 17 Claims |
|
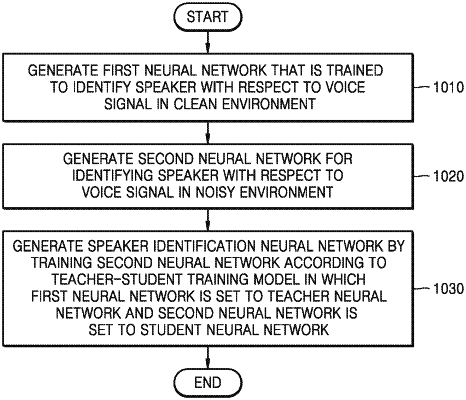
1. A method of generating a speaker identification neural network, the method comprising:
generating a first neural network that is trained to identify a first speaker with respect to a first voice signal in a first environment in which a first signal-to-noise (SNR) value of the first voice signal is greater than or equal to a threshold value, wherein the first neural network is configured to set sentence frames by distinguishing a voice part of the first speaker and a silence part in which only noise exists without voice in the first voice signal, and receive the sentence frames of the first voice signal as an input of the first neural network, and identify the first speaker based on a first sentence embedding vector representing a weighted sum of first embedding vectors that are output from a last hidden layer of the first neural network that is provided immediately before an output layer of the first neural network;
generating a second neural network for identifying a second speaker with respect to a second voice signal in a second environment in which a second SNR value of the second voice signal is less than the threshold value, wherein the second neural network is configured to set sentence frames by distinguishing a voice part of the second speaker and a silence part in which only noise exists without voice in the second voice signal, and receive the sentence frames of the second voice signal as an input of the second neural network, and identify the second speaker based on a second sentence embedding vector indicating a weighted sum of second embedding vectors that are output from a last hidden layer of the second neural network that is provided immediately before an output layer of the second neural network; and
generating the speaker identification neural network by training the second neural network based on a teacher-student training model in which the first neural network is set to a teacher neural network and the second neural network is set to a student neural network,
wherein the speaker identification neural network comprises an attention layer to adjust the initial weights of the second neural network such that a relatively high weight is assigned to an embedding vector of a period in which a voice signal exists, and a relative low weight is assigned to an embedding vector of a period in which a noise signal exists and any voice signal does not exist, among the second embedding vectors.
|