| CPC G06V 40/172 (2022.01) [G06V 10/761 (2022.01); G06V 10/762 (2022.01); G06V 10/774 (2022.01); G06V 10/82 (2022.01)] | 18 Claims |
|
1. A method for training a neural network facial recognition model at scale, comprising:
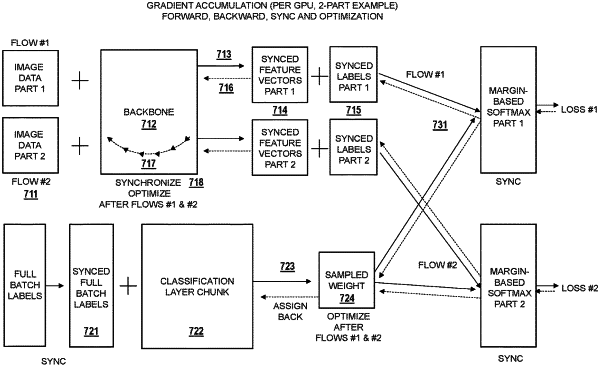
(a) receiving a batch of facial image data and dividing the batch into two or more parts;
(b) performing label synchronization and classification layer sampling using full batch labels and keeping track of the normalized weight as a result of the sampling process;
(c) forwarding a first part of the batch through a neural network backbone distributed in a plurality of GPUs;
(d) synchronizing resulting feature vectors and splitting previously synchronized labels to obtain corresponding labels for the first part of the batch and running forward-backward with sampled weight to compute loss and gradients for sampled weight and feature vectors;
(e) running backward from the feature vectors with the gradients to back-propagate and derive gradients for backbone parameters in each layer;
(f) performing steps (c) to (e) for the part of the two or remaining parts of the batch to allow gradients to accumulate over the first pass for both the sampled weight and the backbone parameters;
(g) synchronizing all the backbone parameters across all of the plurality of GPUs;
(h) running an optimizer for the sample weight and the backbone parameters; and
(i) assigning back the sampled weight and optimizer states to the classification layer.
|