| CPC G06N 20/00 (2019.01) [G06F 16/24 (2019.01); G06F 18/217 (2023.01); G06F 18/2148 (2023.01); G16H 10/60 (2018.01); G16H 15/00 (2018.01); G16H 40/20 (2018.01); G06N 5/04 (2013.01)] | 23 Claims |
|
1. A method performed by a data processing apparatus for training a machine learning model to improve the machine learning model's accuracy, the method comprising:
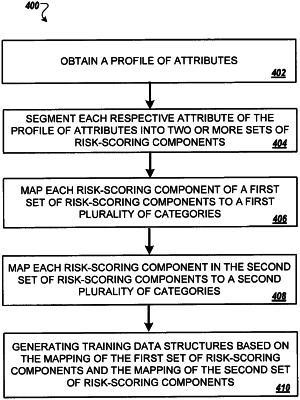
accessing, by a mapping engine, a plurality of risk scoring components associated with an entity;
mapping, by the mapping engine, a first set of risk scoring components, from among the plurality of risk scoring components, to one or more physical health categories based on a first model that recognizes risk scoring components as belonging to the one or more physical health categories;
mapping, by the mapping engine, a second set of risk scoring components, from among the plurality of risk scoring components, to one or more behavioral health categories based on a second model that recognizes the second set of risk scoring components as belonging to the one or more behavioral health categories;
generating a plurality of training data structures, wherein each training data structure includes (i) a plurality of first features derived from the first set of risk scoring components mapped to the one or more physical health categories by the first model and (ii) a plurality of second features derived from the second set of risk scoring components mapped to the one or more behavioral health categories by the second model, wherein generating the plurality of training data structures comprises:
generating a feature vector based on the plurality of first features and the plurality of second features, wherein the feature vector comprises a data field to indicate whether the feature is based on a risk scoring component that is mapped to the one or more physical health categories or is based on a risk scoring component that is mapped to the one or more behavioral health categories; and
assigning, for each first feature from among the plurality of first features, a first value of the data field in the feature vector to indicate that a first corresponding risk scoring component is mapped to the one or more physical health categories;
assigning, for each second feature from among the plurality of second features, a second value of the data field in the feature vector to indicate that a second corresponding risk scoring component is mapped to the one or more behavioral health categories if the second corresponding risk scoring component cannot be mapped to the one or more physical health categories;
obtaining, for each training data structure, a target output;
providing the plurality of training data structures as an input to the machine learning model configured to predict, based on the physical health categories and the behavioral health categories, a risk-level associated with an entity;
determining an amount of error between the predicted risk-level associated with the entity outputted by the machine learning model and the target output of the plurality of training data structures; and
retraining, based on the determined amount of error, the machine learning model after adjusting one or more parameters of the machine learning model.
|