| CPC G06F 40/279 (2020.01) [G06F 18/22 (2023.01); G10L 13/02 (2013.01); G10L 13/08 (2013.01); G10L 15/187 (2013.01)] | 10 Claims |
|
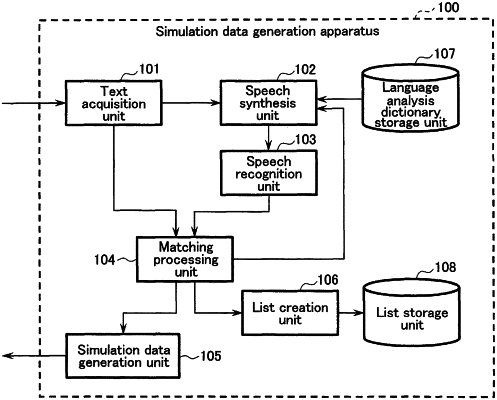
1. A data generation apparatus comprising:
a speech synthesis unit, implemented by circuitry, that generates first speech data from an original text;
a speech recognition unit, implemented by the circuitry, that generates a recognition text from the first speech data by speech recognition, the recognition text being generated using an acoustic model and a language model, the acoustic model and the language model having been previously learned;
a matching processing unit, implemented by the circuitry, that performs matching between the original text and the recognition text; and
a dataset generation unit, implemented by the circuitry, that generates a dataset based on a result of the matching in such a manner that second speech data that has brought about the recognition text where a matching degree to the original text satisfies a certain condition is associated with the original text, the dataset including the second speech data and the original text, the second speech data being included in the first speech data, wherein
if a difference between the recognition text generated from the first speech data and the original text is more than a threshold, the speech synthesis unit generates third speech data assigned at least one of a pronunciation or an accent which is different from that assigned for generating the first speech data.
|