| CPC G06F 11/0793 (2013.01) [G06F 11/079 (2013.01); G06F 11/0724 (2013.01); G06F 11/0751 (2013.01); G06F 16/245 (2019.01); G06Q 10/06311 (2013.01)] | 20 Claims |
|
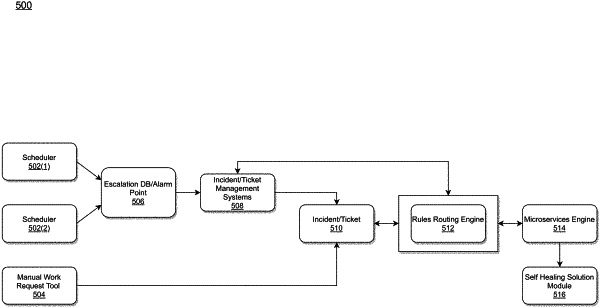
1. A method for identifying production incidents and implementing automated preventive and corrective measures by utilizing one or more processors and one or more memories, the method comprising:
generating an event corresponding to a job failure or service degradation;
generating, by the event, an incident in an automation queue;
automatically triggering, in response to the generated incident, a self-healing service that includes:
identifying an application to which the event generated belongs to by accessing a database that stores the application and host details;
fetching functional identification (ID) of the application from the database, wherein the functional ID allows access to production servers to perform required mitigation steps;
identifying a type of job failure or a service degradation;
automatically executing, by utilizing predefined services, the steps required for mitigation;
recording, in response to executing, outcome of the mitigation in the database along with output at each stage of execution; and
evaluating the outcome of the mitigation by executing health checks to determine whether failed job or a process or a host is healthy; and
closing the incident based on determining that the failed job or the process or the host is healthy.
|