| CPC G06F 9/48 (2013.01) [G06F 9/3001 (2013.01); G06F 9/3004 (2013.01); G06F 9/30036 (2013.01); G06F 9/383 (2013.01)] | 11 Claims |
|
1. A system comprising:
a multi-chip package substrate;
a plurality of heterogeneous dies mounted on the multi-chip package substrate, the heterogeneous dies including:
a plurality of data processing dies, a data processing die comprising:
a first on-chip communication fabric,
a plurality of cores coupled to the first on-chip communication fabric to execute instructions and process data, and
a first serializer/de-serializer (“SerDes”) interconnect coupled to the first on-chip communication fabric, the first SerDes interconnect to communicate over a first one or more data lanes;
an input/output (TO) and memory interconnect die to couple the plurality of cores to a system memory device and one or more IO devices, the IO and memory interconnect die comprising:
a second SerDes interconnect coupled to a second one or more data lanes,
the second SerDes interconnect comprising:
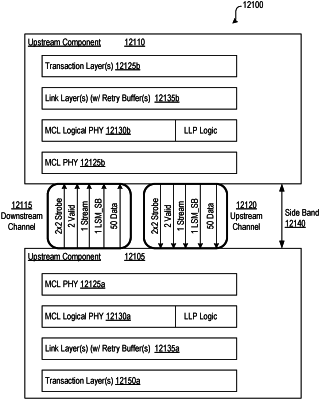
a modular physical layer (PHY) block;
a plurality of protocol-specific logic blocks to communicate data in accordance with a corresponding plurality of data communication protocols, the plurality of protocol-specific logic blocks including a first protocol-specific logic block to communicate first data in accordance with a first data communication protocol and a second protocol-specific logic block to communicate second data in accordance with a second data communication protocol; and
a multiplexer configurable to couple the protocol specific logic blocks to the PHY block;
wherein the first data communication protocol comprises an IO protocol;
a second on-chip communication fabric;
a third SerDes interconnect to communicate over the first one or more data lanes;
a memory controller to couple the plurality of cores to the system memory device; and
an IO memory management unit (IOMMU) coupled to the second on-chip communication fabric, the IOMMU to manage memory accesses on behalf of one or more IO devices coupled to at least one data lane of the second one or more data lanes, the IOMMU to perform virtual-to-physical address translations for memory access requests received over the at least one data lane.
|