| CPC G10L 25/78 (2013.01) [G06F 3/167 (2013.01); G06V 40/18 (2022.01); G06F 40/30 (2020.01)] | 16 Claims |
|
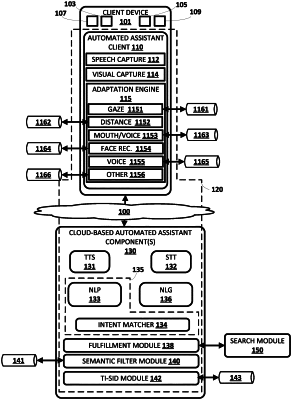
1. A method that facilitates hot-word free interaction between a user and an automated assistant, the method implemented by one or more processors of the client device and comprising:
receiving a stream of image frames that are based on output from one or more cameras of the client device;
processing, at the client device, the image frames of the stream using at least one trained machine learning model stored locally on the client device to detect occurrence of:
a gaze of a user that is directed toward the client device;
rendering, at a display of the client device, a first human perceptible visual cue responsive to detecting the occurrence of the gaze of the user that is directed toward the client device, wherein the first human perceptible visual cue is rendered without simultaneous rendering of a second human perceptible visual cue at the display of the client device;
while rendering the first human perceptible visual cue without simultaneous rendering of the second human perceptible visual cue:
detecting, at the client device, one or multiple of:
voice activity based on local processing of at least part of audio data captured by one or more microphones of the client device;
co-occurrence of mouth movement of the user and the voice activity based on local processing of one or more of the image frames and at least part of the audio data; and
a gesture of the user based on local processing of one or more of the image frames;
in response to continuing to detect occurrence of the gaze, and in response to detecting, during rendering of the first human perceptible visual cue, one or multiple of the voice activity, the co-occurrence of the mouth movement of the user and the voice activity, and the gesture of the user:
supplanting, at the display of the client device, rendering of the first human perceptible visual cue with rendering of the second human perceptible visual cue;
subsequent to rendering the second human perceptible visual cue:
initiating, at the client device, certain additional processing of the audio data and/or of the one or more of the image frames.
|