| CPC G06Q 30/0256 (2013.01) [G06Q 30/0244 (2013.01); G06Q 30/0275 (2013.01); G06Q 30/0277 (2013.01)] | 20 Claims |
|
1. A computer-implemented method for targeting bid and position for a keyword, comprising:
obtaining keyword performance information and keyword value information for the keyword;
generating observations based on the keyword performance information and the keyword value information, the keyword value information being associated with the keyword based on user device tracking and/or user(s) selecting webpages or links displayed at specific positions of lists for the keyword;
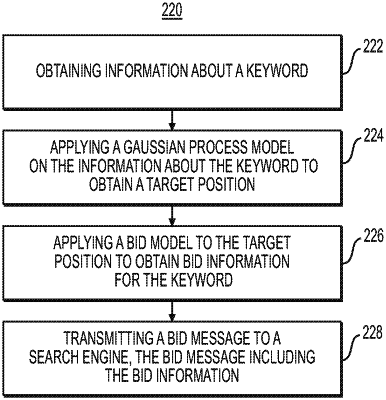
receiving a Gaussian Process Model configured to obtain a prediction function and associated uncertainties;
applying the Gaussian Process Model on the observations to obtain the prediction function and the associated uncertainties relating positions to expected values;
receiving a Thompson sampling reinforcement learning model configured to obtain a target position;
applying the Thompson sampling reinforcement learning model on the expected values and the positions to obtain the target position, the applying the Thompson sampling reinforcement learning model including an agent taking one of one or more action(s) from an action function according to a policy, the one or more action(s) including an exploit action or an explore action, the exploit action or the explore action being chosen according to an exploit-explore ratio of the policy, the policy being updated according to a history of actions, states, and rewards, the rewards corresponding to the values associated with the keyword;
obtaining historical bid position data including a value-position-time set for the keyword;
applying a backwards filtering model to the historical bid position data to form a bid-to-position function;
determining bid information using the target position and the bid-to-position function; and
transmitting a bid message to a search engine, the bid message including the bid information.
|