| CPC G06N 20/00 (2019.01) [G06N 3/063 (2013.01); G06N 3/08 (2013.01); G06N 7/08 (2013.01); G06F 18/214 (2023.01); G06F 18/2411 (2023.01); G06N 5/025 (2013.01); G06N 7/01 (2023.01)] | 16 Claims |
|
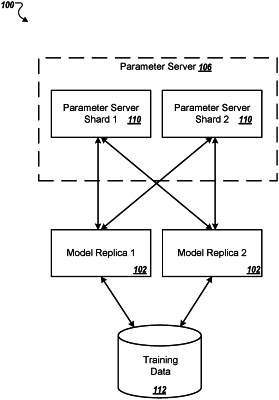
1. A system for training a machine learning model having parameters by determining a respective trained parameter value for each of the parameters of the machine learning model, the system comprising:
one or more server computing units; and
a parameter server executing on the one or more server computing units, wherein the parameter server is configured to maintain and asynchronously update values of each of the parameters of the machine learning model based on delta values received from a plurality of model replicas, wherein each model replica executes on a respective replica computing unit, wherein each of the plurality of model replicas is configured to maintain an identical instance of the machine learning model with possibly different parameter values for the parameters of the machine learning model and to operate independently of each other model replica, and wherein each model replica is further configured to asynchronously request parameter values from the parameter server, determine delta values for the parameters based on stochastic gradient descent, and provide the delta values to the parameter server.
|