| CPC G06F 40/295 (2020.01) [G06F 40/30 (2020.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A method comprising:
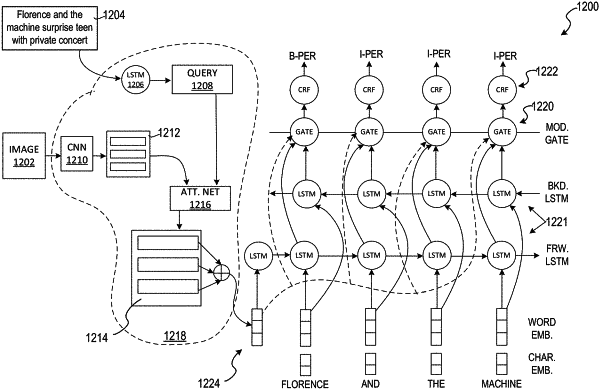
identifying, using one or more processors of a machine, a multimodal message that includes an image and a caption comprising words;
generating, using an attention neural network, a visual context vector from the caption and the image, the visual context vector emphasizing portions of the caption based on objects depicted in the image;
generating, using an entity recognition neural network, an indication that one or more words of the caption correspond to a named entity;
integrating, using a modulation layer, the visual context vector into the entity recognition neural network for each word in the caption; and
storing the one or more words as the named entity of the multimodal message.
|