| CPC H04R 1/406 (2013.01) [G06F 3/012 (2013.01); G06N 3/08 (2013.01); G10L 25/30 (2013.01); H04R 3/005 (2013.01)] | 20 Claims |
|
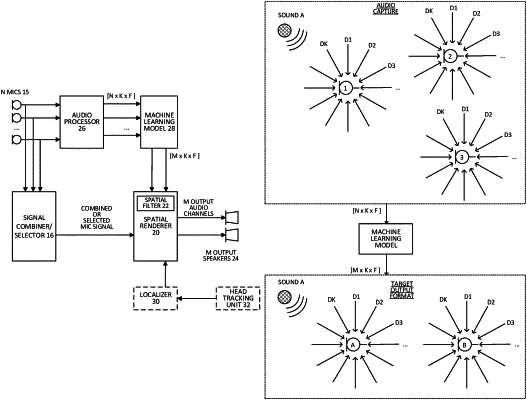
1. A method for spatial audio reproduction comprising:
obtaining a plurality of microphone signals representing sounds sensed by a plurality of microphones;
providing, as input to a machine learning model, a frequency response for each of a plurality of directions around each of the plurality of microphones;
obtaining, from the machine learning model, an output frequency response for each of a second plurality of directions associated with audio channels of a target audio output format; and
applying spatial filter parameters, determined based on the output frequency response, to one or more microphone signals selected from the plurality of microphone signals, resulting in output audio signals for each of the audio channels of the target audio output format.
|