| CPC G10L 25/78 (2013.01) [G06F 18/214 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06N 5/046 (2013.01); G06N 20/20 (2019.01); G10L 15/16 (2013.01)] | 22 Claims |
|
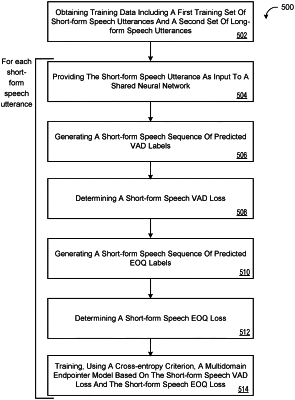
1. A computer-implemented method when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving, as input to a multidomain endpointer model, a sequence of audio features representing an utterance captured by a microphone of a user device, the multidomain endpointer model comprising a shared neural network trained on:
a first training set of short-form speech utterances; and
a second training set of long-form speech utterances;
generating, as output from the multidomain endpointer model, a sequence of predicted end-of-query (EOQ) speech labels comprising a predicted EOQ speech label, a predicted EOQ initial silence label, a predicted EOQ intermediate silence label, and a predicted EOQ final silence label; and
when the predicted EOQ final silence label is output from the multidomain endpointer model, obtaining a hard microphone closing decision that causes the user device to endpoint the utterance by deactivating the microphone.
|