| CPC G10L 17/18 (2013.01) [G10L 15/02 (2013.01); G10L 17/02 (2013.01)] | 20 Claims |
|
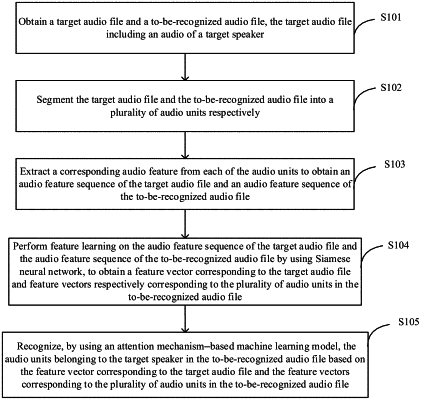
1. A speaker recognition method, comprising:
obtaining a target audio file and a to-be-recognized audio file, the target audio file comprising an audio of a target speaker;
segmenting the target audio file and the to-be-recognized audio file into a plurality of audio units respectively;
extracting a corresponding audio feature from each of the audio units to obtain an audio feature sequence of the target audio file and an audio feature sequence of the to-be-recognized audio file;
performing feature learning on the audio feature sequence of the target audio file and the audio feature sequence of the to-be-recognized audio file by using Siamese neural network, to obtain a feature vector corresponding to the target audio file and feature vectors respectively corresponding to the plurality of audio units in the to-be-recognized audio file; and
recognizing, by using an attention mechanism-based machine learning model, the audio units belonging to the target speaker in the to-be-recognized audio file based on the feature vector corresponding to the target audio file and the feature vectors respectively corresponding to the plurality of audio units in the to-be-recognized audio file.
|