| CPC G10L 15/26 (2013.01) [G10L 15/22 (2013.01); G10L 15/065 (2013.01); G10L 15/083 (2013.01); G10L 15/1822 (2013.01); G10L 2015/223 (2013.01); G10L 2015/228 (2013.01)] | 20 Claims |
|
1. A method implemented by one or more processors of a client device, the method comprising:
generating, using a locally stored list of relevant context sensitive entities, voice to text model update data for a context sensitive parameter that is associated with the relevant context sensitive entities, wherein the voice to text model update data comprises decoding paths for the relevant context sensitive entities;
subsequent to generating the voice to text model update data:
receiving a voice input with a voice-enabled electronic device, the voice input including an original request that includes first and second portions, the second portion including a first context sensitive entity among the relevant context sensitive entities; and
in the voice-enabled electronic device, and responsive to receiving the first portion of the voice input:
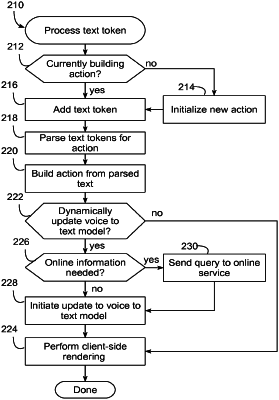
performing local processing of the first portion of the voice input;
determining during the local processing that the first portion is associated with the context sensitive parameter;
in response to determining that the first portion is associated with the context sensitive parameter:
dynamically updating a local voice to text model, used by the voice-enabled electronic device, using the locally generated voice to text model update data, wherein dynamically updating the local voice to text model facilitates recognition of the first context sensitive entity in performing local processing of the second portion of the voice input;
generating, utilizing the dynamically updated local voice to text model, a recognition of the second portion of the voice input; and
causing performance of a voice action that is based on the recognition of the second portion of the voice input.
|