| CPC G10L 15/26 (2013.01) [G06F 40/289 (2020.01); G10L 15/1822 (2013.01); G06F 21/30 (2013.01); G06F 21/316 (2013.01); G06F 40/253 (2020.01); G10L 17/02 (2013.01)] | 20 Claims |
|
20. A system comprising:
one or more processors programmed with instructions that, when executed by the one or more processors, cause operations comprising:
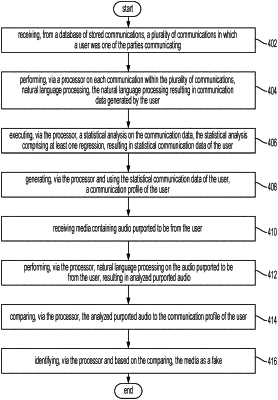
receiving, from a database, a plurality of communications in which a user participated;
performing natural language processing on the plurality of communications to obtain communication data associated with the user;
executing a statistical analysis on the communication data to obtain statistical communication data of the user;
generating, using the statistical communication data of the user, a communication profile of the user, the communication profile comprising a data structure storing a user identifier associated with a personalized linguistic syntax of the user and the statistical communication data of the user;
receiving media containing audio purported to be from the user;
performing natural language processing on audio purported to be from the user to obtain analyzed audio;
comparing a syntax of analyzed audio to the personalized linguistic syntax stored within the communication profile of the user to obtain a syntax similarity score;
comparing words used within analyzed audio with the statistical communication data of the user to obtain a word usage similarity score; and
identifying, based on the syntax similarity score and the word usage similarity score, the media as a fake.
|