| CPC G10L 15/16 (2013.01) [G06F 18/214 (2023.01); G06F 18/24133 (2023.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/048 (2023.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01); G06V 10/454 (2022.01); G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01); G10L 25/18 (2013.01); G10L 25/24 (2013.01); G10L 15/197 (2013.01); G10L 2015/0635 (2013.01); G10L 2015/081 (2013.01)] | 20 Claims |
|
1. A system comprising one or more processors, and a non-transitory computer-readable medium including one or more sequences of instructions that, when executed by the one or more processors, cause the system to perform operations comprising:
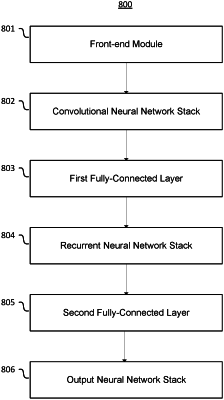
providing a trained speech recognition neural network, the speech recognition neural network including a plurality of layers each having a plurality of nodes;
transcribing speech audio by the speech recognition neural network;
generating one or more feature representations from a subset of the nodes;
receiving a first set of classifications for a first portion of the speech audio;
providing a trained a classification model, the classification model trained on a first set of feature representations corresponding to the first portion of the speech audio and the first set of classifications; and
determining a second set of classifications for a second portion of the speech audio by inputting a second set of feature representations corresponding to the second portion of the speech audio into the trained classification model, the second set of feature representations comprising a second subset of the feature representations generated during the speech audio transcription.
|