| CPC G10L 13/10 (2013.01) [G10L 13/04 (2013.01); G10L 25/30 (2013.01); G06N 3/044 (2023.01); G10L 13/02 (2013.01); G10L 13/08 (2013.01)] | 22 Claims |
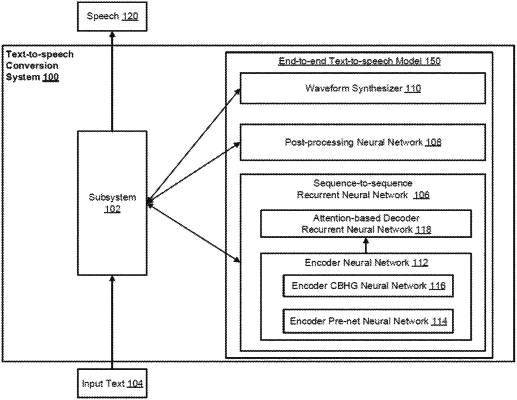
|
1. A system comprising:
a context encoder configured to:
receive one or more context features associated with current input text to be synthesized into expressive speech, each context feature derived from a text source of the current input text; and
process the one or more context features to generate a context embedding associated with the current input text;
a text encoder configured to:
receive the current input text from the text source; and
process the current input text to generate a text encoding of the current input text;
a text-prediction network in communication with the context encoder and configured to:
receive the text encoding of the current input text from the text encoder, the text source comprising sequences of text to be synthesized into expressive speech;
receive the context embedding associated with the current input text from the context encoder; and
process the text encoding of the current input text and the context embedding associated with the current input text to predict, as output, a style embedding for the current input text, the style embedding specifying a specific prosody and/or style for synthesizing the current input text into expressive speech,
wherein the text-prediction network comprises:
a time-aggregating gated recurrent unit (GRU) recurrent neural network (RNN) configured to:
receive the context embedding associated with the current input text and the text encoding of the current input text; and
generate a fixed-length feature vector by processing the context embedding and the text encoding; and
one or more fully-connected layers configured to predict the style embedding by processing the fixed-length feature vector; and
a text-to-speech model in communication with the text-prediction network and configured to:
receive the current input text from the text source;
receive the style embedding predicted by the text-predication network; and
process the current input text and the style embedding to generate an output audio signal of expressive speech of the current input text, the output audio signal having the specific prosody and/or style specified by the style embedding.
|