| CPC G10L 13/08 (2013.01) [G10L 15/187 (2013.01)] | 24 Claims |
|
13. A system comprising:
data processing hardware; and
memory hardware in communication with the data processing hardware, the memory hardware storing instructions that, when executed on the data processing hardware, cause the data processing hardware to perform operations comprising:
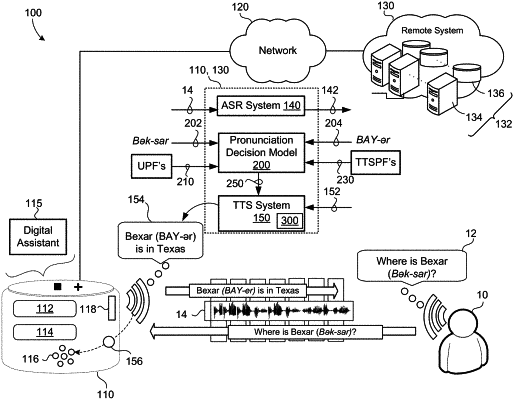
receiving a user pronunciation of a particular word present in a query spoken by a user;
receiving a text-to-speech (TTS) pronunciation of the same particular word that is present in a TTS input, the TTS input comprising a textual representation of a response to the query, and the TTS pronunciation of the particular word is different than the user pronunciation of the particular word;
obtaining user pronunciation-related features associated with the user pronunciation of the particular word;
obtaining TTS pronunciation-related features associated with the TTS pronunciation of the particular word;
generating, as output from a pronunciation decision model configured to receive the user pronunciation-related features and the TTS pronunciation-related features as input, a pronunciation decision selecting the one of the user pronunciation of the particular word or the TTS pronunciation of the particular word that is associated with a highest confidence for use in TTS audio;
synthesizing, using a TTS system, the TTS audio by converting the textual representation of the response to the query into the TTS audio using the one of the user pronunciation of the particular word or the TTS pronunciation of the particular word that was selected by the pronunciation decision output from the pronunciation decision model; and
providing, for audible output from a user device associated with the user, the TTS audio, the TTS audio comprising a synthesized speech representation of the response to the query.
|