| CPC G06T 1/20 (2013.01) [G06F 7/5443 (2013.01); G06F 9/5027 (2013.01); G06F 12/0806 (2013.01); G06F 15/8046 (2013.01); G06F 17/16 (2013.01); G06N 3/048 (2023.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01)] | 20 Claims |
|
1. A general purpose graphics processor comprising:
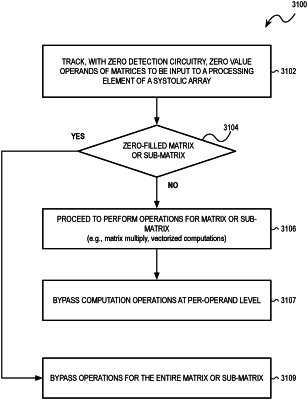
a processing resource including a matrix accelerator and a decoder, the matrix accelerator including a load filter to bypass a load of a sparse submatrix of an input matrix and the decoder to decode an encoded set of data associated with the input matrix to generate a decoded set of data, the decoder to decode the encoded set of data based on metadata associated with the encoded set of data, wherein the load filter is to bypass the load of the sparse submatrix based on the metadata associated with the encoded set of data,
the load filter configured to bypass a load of a near-sparse submatrix having a limited number of non-zero values; and
the matrix accelerator configured to send a message to indicate bypass of the near-sparse submatrix.
|