| CPC G06N 20/00 (2019.01) [G06N 5/02 (2013.01)] | 20 Claims |
|
1. A non-transitory computer readable medium storing instructions which, when executed by one or more computing devices, cause the one or more computing devices to perform a process of:
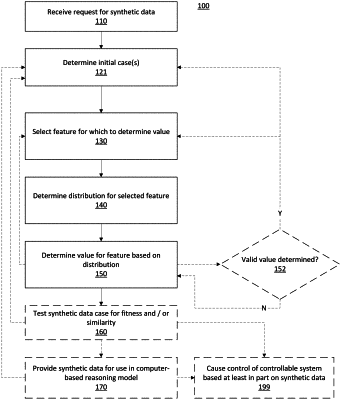
receiving a request for generation of synthetic data based on a set of training data cases;
determining one or more focal training data cases from among the set of training data cases;
determining a synthetic data case based on the one or more focal training data cases;
determining whether the synthetic data case is overly similar to one or more cases in the set of training data cases;
when the synthetic data case is determined to be overly similar to one or more cases in the set of training data cases, taking corrective action for the synthetic data case to produce a new synthetic data case and using the new synthetic data case for consideration in adding to a set of synthetic training data cases;
when the synthetic data case is determined to not be overly similar to cases in the set of training data cases, adding the synthetic data case to the set of synthetic training data cases.
|