| CPC G06N 20/00 (2019.01) [G05B 13/04 (2013.01); G05B 19/406 (2013.01)] | 14 Claims |
|
1. A system for controlling an operation of a machine subject to state constraints in continuous state space of the machine and subject to control input constraints in continuous control input space of the machine, comprising:
an input interface to accept data indicative of a state of the machine;
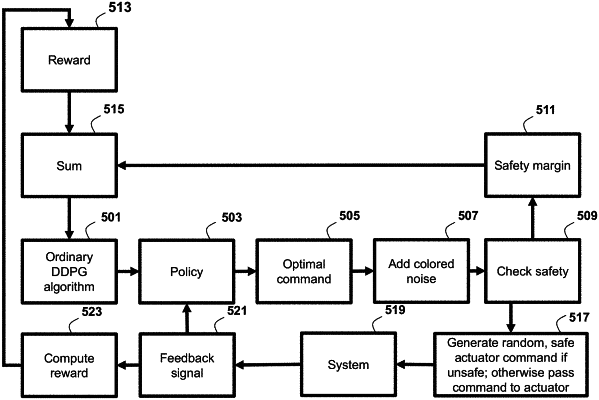
a memory configured to store an optimization problem for computing a safety margin of a state and action pair satisfying the state constraints and a control policy mapping the state of the machine within a control invariant set (CIS) to a control input satisfying the control input constraints, wherein a control of the machine having the state within the CIS according to the control policy maintains the state of the machine within the CIS, wherein the memory includes a supervisor algorithm that obtains the state of the machine and computes a desired safety margin, wherein the supervisor algorithm generates a safe command when a reinforcement learning (RL) algorithm generates a command that is deemed unsafe, wherein the safe command is a modification of the unsafe command according to optimization (SO):
c(t)=min α Σk=1N∥u(k|t)∥1,
where c(t) is a cost function, u (k|t) is a command vector predicted value of u(t+k), α is a scaling factor, k, N are integers, t is a current time of the system; and
a processor configured to iteratively perform the RL algorithm to jointly control the machine and update the control policy, wherein, for performing the joint control and update, the processor is configured to
control the machine using the control policy to collect data including a sequence of control inputs generated using the control policy and a sequence of states of the machine corresponding to the sequence of control inputs;
determine a reward for a quality of the control policy on the state of the machine using a reward function of the sequence of control inputs and the sequence of states of the machine augmented with an adaptation term determined as the minimum amount of effort needed for the machine having the state to remain within the CIS; and
update the control policy that improves a cost function of operation of the machine according to the determined reward.
|