| CPC G06N 3/063 (2013.01) [G06F 17/15 (2013.01); G06F 17/16 (2013.01); G06N 3/084 (2013.01); G06N 20/00 (2019.01)] | 23 Claims |
|
1. A computing system comprising:
a computer-readable memory storing an operational parameter of a given layer of a neural network; and
a hardware accelerator in communication with the computer-readable memory for accelerating tensor operations, the hardware accelerator configured to:
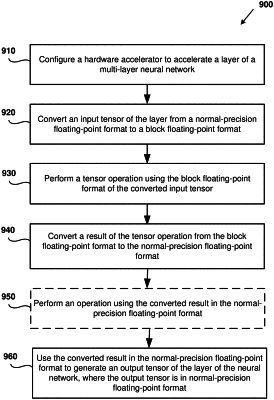
receive an input tensor for a given layer of a multi-layer neural network;
convert the input tensor from a normal-precision floating-point format to a quantized-precision floating-point format, the quantized-precision floating-point format being a block floating-point format, wherein a first converted input tensor portion corresponding to a first portion of the input tensor comprises a first common exponent for values in the first portion of the input tensor and a first plurality of mantissa values and a second converted tensor portion corresponding to a second portion of the input tensor comprises a second common exponent value for values in the second portion of the input tensor and a second plurality of mantissa values, wherein the first common exponent is different than the second common exponent;
perform a tensor operation using the input tensor converted to the quantized-precision floating-point format;
convert a result of the tensor operation from the quantized-precision floating-point format to the normal-precision floating-point format to provide a converted result in the normal-precision floating-point format; and
in a training iteration of a plurality of iterations of training of the multi-layer neural network, updating the operational parameter of the given layer of the multi-layer neural network stored in the computer-readable memory using the converted result in the normal precision floating-point format, where the operational parameter of the given layer of the neural network is stored in normal-precision floating-point format.
|