| CPC G06F 40/284 (2020.01) [G06F 40/216 (2020.01); G06F 40/30 (2020.01)] | 20 Claims |
|
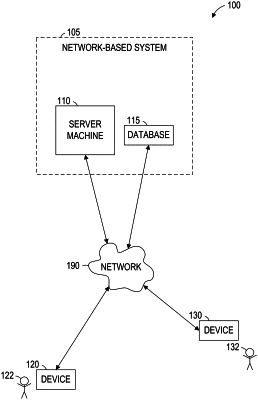
1. A method for tokenizing text for natural language processing, the method comprising:
generating, by one or more processors in a natural language processing platform, and from a pool of documents, a set of statistical models comprising one or more entries each indicating a likelihood of appearance of a character/letter sequence in the pool of documents;
receiving, by the one or more processors, a set of rules comprising rules that identify character/letter sequences as valid tokens;
transforming, by the one or more processors, one or more entries in the statistical models into new rules that are added to the set of rules when the entries indicate a high likelihood;
receiving, by the one or more processors, a document to be processed;
dividing, by the one or more processors, the document to be processed into tokens based on the set of statistical models and the set of rules; and
outputting, by the one or more processors, the tokens for natural language processing.
|