| CPC G06F 40/237 (2020.01) [G06F 16/90344 (2019.01); G06F 40/242 (2020.01); G06F 40/279 (2020.01); G06F 40/30 (2020.01)] | 13 Claims |
|
1. A computer-implemented method, comprising:
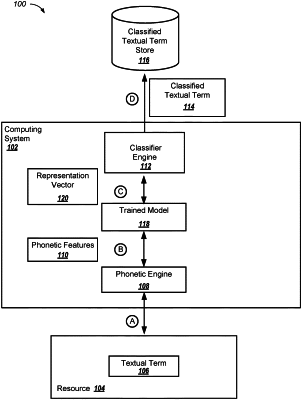
obtaining an unknown textual term and other terms surrounding the unknown textual term with N word positions of the unknown textual term, wherein the unknown textual term is a textual term that has an unknown dictionary definition, and N is a predetermined integer value;
determining, by one or more computers, an unknown term vector representing (i) one or more phonetic features of the unknown textual term and (ii) the other terms surrounding the unknown textual term, including determining the unknown term vector using (i) the one or more phonetic features of the unknown textual term and (ii) the one or more other textual terms that are surrounding the unknown textual term;
classifying the unknown textual term based on (i) a word-based model that uses the representation of the one or more other textual terms that are surrounding the unknown textual term to classify the unknown textual term; and (ii) a classifier that compares the representation of the one or more phonetic features of the unknown textual term to each of a plurality of reference vectors in a vector space, wherein each reference vector represents a reference textual term having a known definition;
wherein classifying the unknown textual term comprises:
determining a level of similarity between the unknown textual term vector and each of the plurality of reference vectors; and
generating a classified textual term that includes a word score vector comprised of a plurality of fields that each correspond to a respective reference textual term having a known dictionary definition, wherein generating the classified textual term further includes determining a score for each respective field of the word score vector that is (i) based on the similarity determination of the unknown textual vector and the reference vector that represents the respective reference textual term that is associated with the respective field, and (ii) indicative of the probability that the definition of the unknown textual term corresponds to the definition of the respective reference textual term that is associated with the respective field; and
providing the classified textual term as an input to a word model, wherein the word model is configured to process the classified textual term and generate one or more representation vectors, based on the classified textual term.
|