| CPC G06F 30/27 (2020.01) [G06F 30/392 (2020.01)] | 20 Claims |
|
1. A method performed by one or more computers, the method comprising:
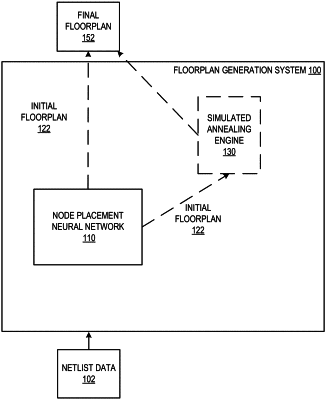
obtaining netlist data for a computer chip, wherein the netlist data specifies a connectivity on a computer chip between a plurality of nodes that each correspond to one or more of a plurality of integrated circuit components of the computer chip;
generating a computer chip floorplan that places each node in the netlist data at a respective position on the surface of the computer chip using a node placement neural network that comprises (i) an input subnetwork configured to, at each of a plurality of time steps, process an input representation for the time step to generate an embedding of the input representation; and (ii) a policy subnetwork configured to, at each of the plurality of time steps, process the embedding of the input representation for the time step to generate a score distribution over a plurality of positions on the surface of the computer chip;
generating, using a reward function that measures a quality of the computer chip floorplan, a reward for the computer chip floorplan; and
training, using at least the reward, at least the policy subnetwork of the node placement neural network through reinforcement learning to generate probability distributions that maximize the reward function.
|