| CPC G06F 16/2246 (2019.01) [G06F 16/285 (2019.01); G06F 16/9024 (2019.01)] | 18 Claims |
|
1. A system, comprising:
one or more processors and corresponding memory of one or more computing devices;
wherein the memory of the one or more computing devices includes instructions that upon execution on or across the one or more processors cause the one or more computing devices to:
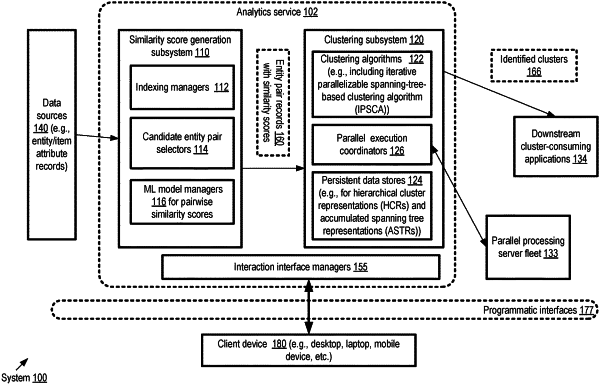
generate, using a plurality of analysis iterations, a hierarchical representation of an input data set, wherein the input data set comprises a plurality of entity pairs and respective similarity scores for the entity pairs, and wherein a particular analysis iteration of the plurality of analysis iteration comprises at least:
identifying, from an input entity pair collection of the particular iteration, a subset of pairs with a similarity score above a similarity threshold of the particular iteration;
generating, from the subset of pairs, one or more clusters, wherein a particular cluster comprises a respective plurality of nodes such that at least one path comprising one or more edges exists between a given pair of nodes, wherein individual ones of the nodes correspond to respective entities represented in the subset of pairs, and wherein individual ones of the edges correspond to respective pairs of the subset of pairs;
identifying, corresponding to individual ones of the clusters, a respective spanning tree;
adding, to an accumulated spanning tree representation, one or more edges of a particular spanning tree of the respective spanning trees, wherein the accumulated spanning tree representation comprises at least some edges of a spanning tree identified in a previous analysis iteration;
adding, to the hierarchical representation, at least an indication of a representative node selected from the particular spanning tree; and
excluding, using at least the accumulated spanning tree representation and an inter-spanning-tree edge reduction algorithm, at least some of the entity pairs of the input entity pair collection of the particular analysis iteration from an input entity pair collection for a subsequent analysis iteration;
store the hierarchical representation; and
in response to a run-time clustering request, received via a programmatic interface, utilize the stored hierarchical representation to provide an indication of a plurality of entities of the input data set which satisfy an intra-cluster similarity criterion.
|