| CPC G06F 12/0207 (2013.01) [G06F 5/01 (2013.01); G06F 7/501 (2013.01); G06F 7/523 (2013.01); G06F 9/30054 (2013.01); G06F 9/5016 (2013.01); G06F 9/5027 (2013.01); G06F 12/02 (2013.01); G06F 12/0646 (2013.01); G06F 12/0692 (2013.01); G06F 13/1663 (2013.01); G06F 17/10 (2013.01); G06F 18/00 (2023.01); G06F 30/27 (2020.01); G06F 30/30 (2020.01); G06N 3/02 (2013.01); G06N 3/04 (2013.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01); G06N 20/00 (2019.01); G06N 3/082 (2013.01); Y02D 10/00 (2018.01)] | 20 Claims |
|
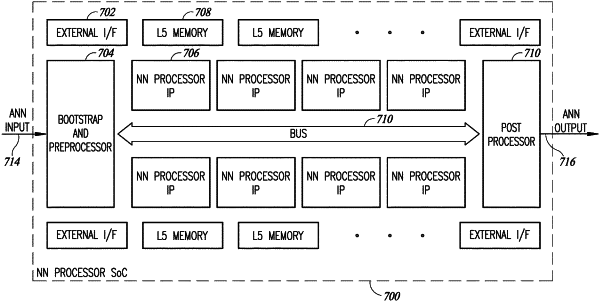
1. A neural network (NN) processor system on chip (SoC) for performing neural network calculations for an artificial neural network (ANN) having one or more network layers, comprising: a plurality of NN processor cores, each NN processor core comprising a data plane including a plurality of processing element circuits, each processing element circuit including computing elements for performing neural network calculations and associated dedicated memory elements; wherein said plurality of processing element circuits, including computing elements and associated dedicated memory elements, are aggregated in multiple levels to form a programmable hierarchy, where each level is configurable and has its own dedicated local memory;
each NN processor core also comprising a control plane separate from said data plane and including one or more layer controllers operative to generate control signaling and configured to be dynamically mapped to sets of processing element circuits in accordance with a number of computations required in a network layer;
an internal bus providing synchronous communications between said plurality of NN processor cores utilizing a synchronous protocol as well as guaranteeing a required bandwidth therebetween;
wherein during an offline compilation process a compiler maps on a layer by layer basis a logical ANN model to a physical configuration that includes a plurality of NN processor cores whereby processing for said logical ANN model is split across said plurality of NN processor cores in accordance with bandwidth demand at an input and output of any ANN subnetworks mapped to said plurality of NN processor cores;
and wherein said mapping and resultant physical configuration are driven by available resources of each NN processor core, including memory capacity, computing capacity, availability of control resources, and input and output ports each having limited bandwidth.
|