| CPC G06F 3/0644 (2013.01) [G06F 3/067 (2013.01); G06F 3/0611 (2013.01); G06F 12/0223 (2013.01); G06F 12/0804 (2013.01)] | 18 Claims |
|
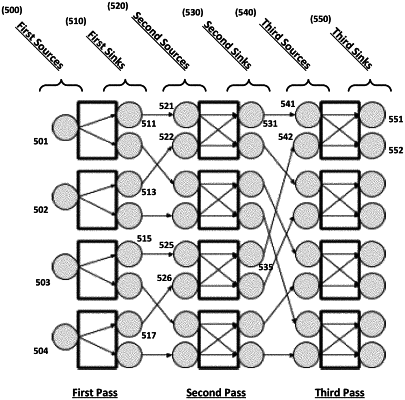
1. A method of repartitioning data in a distributed network, the method comprising:
executing, by one or more first processors, a first shuffle of a first portion of a data set from a plurality of first sources to a plurality of first sinks, each first sink collecting data from one or more of the first sources;
tracking, by the one or more first processors, metadata of the first portion of the data set during the first shuffle;
executing, by the one or more second processors separate from the one or more first processors, a second shuffle of a second portion of the data set from the plurality of first sources to a plurality of second sinks, each second sink collecting data from one or more of the first sources; and
tracking, by the one or more second processors, metadata of the second portion of the data set during the second shuffle,
wherein executing the first and second shuffles causes the data set to be repartitioned such that one or more first sinks and one or more second sinks collect data that originated from two or more of the first sources.
|