| CPC G10L 19/0212 (2013.01) [G10L 19/022 (2013.01)] | 14 Claims |
|
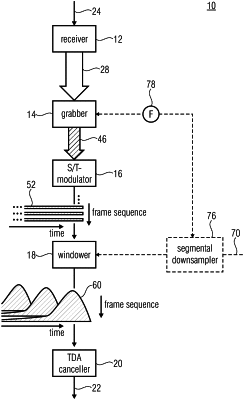
1. Audio decoder configured to decode an audio signal at a first sampling rate from a data stream into which the audio signal is transform coded at a second sampling rate, the first sampling rate being 1/Fth of the second sampling rate, the audio decoder comprising:
a receiver configured to receive, per frame of length N of the audio signal, N spectral coefficients;
a grabber configured to grab-out for each frame, a low-frequency fraction of length N/F out of the N spectral coefficients;
a spectral-to-time modulator configured to subject, for each frame, the low-frequency fraction to an inverse transform having modulation functions of length (E+2)·N/F temporally extending over the respective frame and E+1 previous frames so as to obtain a temporal portion of length (E+2)·N/F;
a windower configured to window, for each frame, the temporal portion using a synthesis window of length (E+2)·N/F comprising a zero-portion of length ¼·N/F at a leading end thereof and having a peak within a temporal interval of the synthesis window, the temporal interval succeeding the zero-portion and having length 7/4·N/F so that the windower obtains a windowed temporal portion of length (E+2)·N/F; and
a time domain aliasing canceler configured to subject the windowed temporal portion of the frames to an overlap-add process so that a trailing-end fraction of length (E+1)/(E+2) of the windowed temporal portion of a current frame overlaps a leading end of length (E+1)/(E+2) of the windowed temporal portion of a preceding frame,
wherein the inverse transform is an inverse MDCT or inverse MDST, and
wherein the synthesis window is a downsampled version of a reference synthesis window of length (E+2)·N, downsampled by a factor of F by a segmental interpolation in segments of length ¼·N,
wherein the receiver is configured to use entropy decoding in order to read the spectral coefficients from the data stream and spectrally shape the spectral coefficients with scale factors provided in the data stream or scale factors derived by linear prediction coefficients conveyed within data stream.
|