| CPC G10L 15/22 (2013.01) [G10L 15/16 (2013.01)] | 22 Claims |
|
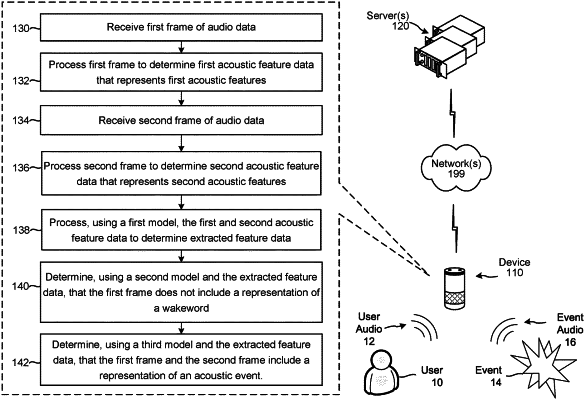
1. A computer-implemented method, comprising:
determining a feature vector representing at least one frame of audio data;
determining, using a first model and the feature vector, first output data corresponding to a likelihood that the at least one frame includes a representation of at least part of a word; and
determining, using a second model different from the first model and the feature vector, second output data corresponding to a likelihood that the at least one frame includes a representation of at least part of a non-speech acoustic event, wherein determination of the second output data is performed independently of the first output data.
|