| CPC G10L 15/22 (2013.01) [G06N 3/08 (2013.01); G06T 13/00 (2013.01); G10L 15/16 (2013.01); G10L 15/1815 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A device for improving output content through iterative generation, the device comprising:
at least one processor; and
a memory storing instructions which, when executed by the at least one processor, cause the at least one processor to:
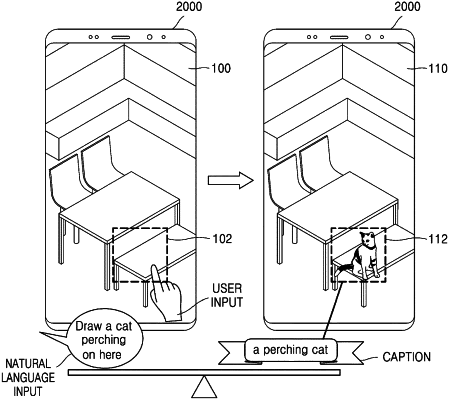
receive a natural language input while displaying base content,
based on the natural language input, obtain user intention information by using a natural language understanding (NLU) model,
based on a first user input, set a target area in the base content,
based on the user intention information or a second user input, determine input content,
based on the input content, the target area, and the user intention information, generate output content related to the base content by using a neural network (NN) model, the NN model being related to a generated adversarial network (GAN) model,
generate a caption for the output content by using an image captioning model,
calculate a similarity between text of the natural language input and the output content, and
based on the similarity, iterate the generation of the output content,
wherein the output content comprises first output content, and
wherein the instructions, when executed by the at least one processor, further cause the at least one processor to:
in response to the similarity not satisfying a predetermined condition, generate second output content different from the first output content based on the input content, the target area, and the user intention information by using the NN model.
|