| CPC G10L 13/08 (2013.01) [G10L 13/04 (2013.01); G10L 15/187 (2013.01); G10L 2015/025 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
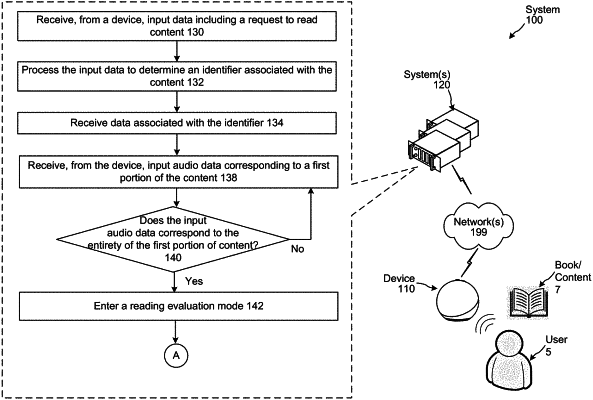
receiving, from a device, first input audio data representing a spoken natural language input including a request to read a book, the first input audio data associated with a session identifier;
processing the first input audio data to determine a book identifier associated with the book;
receiving first text data associated with the book identifier, the first text data representing a first portion of the book;
receiving, from the device, second input audio data including speech corresponding to the first portion of the book, the second input audio data associated with the session identifier;
determining that the second input audio data corresponds to an entirety of the first portion of the book;
determining, using a trained machine learning (ML) model, first reading evaluation data based on the second input audio data and the first text data, the first reading evaluation data associated with the session identifier;
based on the first reading evaluation data, determining to output a second portion of the book;
receiving second text data associated with the book identifier, the second text data representing the second portion of the book;
performing text-to-speech (TTS) processing on the second text data to generate first output audio data representing the second portion of the book; and
sending the first output audio data to the device.
|