| CPC G06V 20/47 (2022.01) [G06V 20/41 (2022.01); G06V 20/49 (2022.01); G11B 27/034 (2013.01); G11B 27/34 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
extracting visual and audio content of a target video;
parsing the target video into segments based on the extracted visual and audio content;
generating, utilizing a trained sentiment classifier machine learning model to analyze visual embeddings of individual frames to predict a visual sentiment of each individual frame, frame sentiment embeddings for frames of the target video and a sentiment distribution for one or more videos previously viewed by a user of a computing device;
generating a user preference vector based on the sentiment distribution for the one or more videos previously viewed by the user;
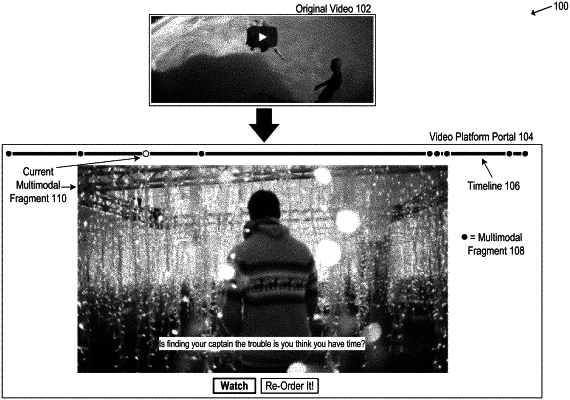
generating, by a multimodal fragment generation model, multimodal fragments corresponding to the segments of the target video, wherein the multimodal fragments comprise visual components and textual components extracted from the segments;
generating, utilizing a trained context classifier machine learning model to analyze the frames of the target video, a video-level context embedding of contextual information for the target video and segment-level context embeddings of contextual information for the segments of the target video;
determining a nonlinear ordering of the multimodal fragments by comparing the user preference vector with sets of frame sentiment embeddings for frames of the target video corresponding to the multimodal fragments and comparing the video-level context embedding with the segment-level context embeddings corresponding to the multimodal fragments; and
causing, at the computing device, playback of the segments in accordance with the nonlinear ordering of the multimodal fragments.
|