| CPC G06Q 40/03 (2023.01) [G06N 20/00 (2019.01); G06Q 40/00 (2013.01)] | 18 Claims |
|
1. A method comprising:
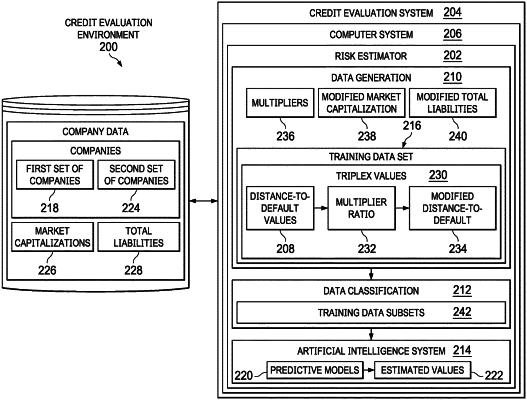
creating, by a risk estimator of a computer system, a training data set from distance-to-default values for a first set of companies, wherein the risk estimator comprises an artificial intelligence system;
building, by the risk estimator of the computer system, a set of predictive models based on the training data set, wherein the artificial intelligence system comprises the set of predictive models and machine learning of the artificial intelligence system is used to train the set of predictive models using the training data set;
forecasting, by the risk estimator of the computer system, an estimated change in distance-to-default values for a second set of companies according to the set of predictive models; and
assessing, by the risk estimator of the computer system, a credit risk of the second set of companies according to the estimated change in distance-to-default values,
wherein creating the training data set further comprises:
identifying market capitalizations and total liabilities for the first set of companies; and
for each of the first set of companies, determining the distance-to-default values according to the market capitalization and total liabilities of the first set of companies, and
wherein the distance-to-default values for the first set of companies is determined according to:
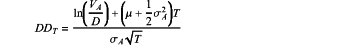 wherein:
DDT is a distance-to-default at time T;
VA is an asset value;
D is total liabilities;
μ is a mean asset return;
σA is an asset volatility; and
T is a time horizon,
wherein creating a training data set further comprises:
for each of the first set of companies, generating a set of triplex values from a multiplier ratio, the distance-to-default values for the first set of companies, and modified distance-to-default values for the first set of companies, wherein the training data set comprises the set of triplex values, and
wherein building the set of predictive models further comprises:
separating the set of triplex values into training data subsets, wherein the set of triplex values are separated according to the multiplier ratio and the distance-to-default values of the first set of companies; and
building predictive models based on each of the training data subsets.
|