| CPC G06N 3/08 (2013.01) [G06F 40/20 (2020.01)] | 4 Claims |
|
1. A method for meta-knowledge fine-tuning based on domain-invariant features, comprising the following stages:
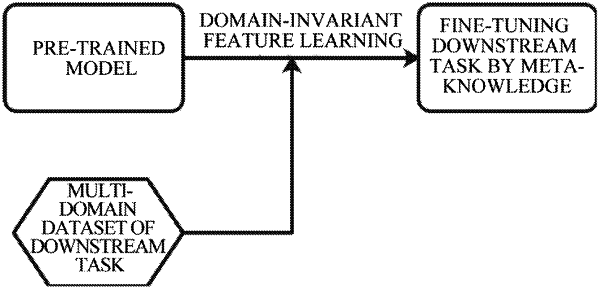
a first stage of constructing an adversarial domain classifier: adding the adversarial domain classifier by meta-knowledge fine-tuning to optimize downstream tasks, in order that the adversarial domain classifier is driven to be capable of distinguishing categories of different domains, constructing the adversarial domain classifier, wherein a loss optimization needs to be executed to reduce a performance of the adversarial domain classifier, so that the domain classifier is capable of predicting real domain labels; in order that a prediction probability of the adversarial domain classifier is any degree of one or more predicted wrong labels when the loss function of an exchange domain is minimized, the classifier performs a prediction on a label of a direct exchange domain to minimize the loss function of the exchange domain, so that the learned features are independent of the domain;
a second stage of constructing an input feature, wherein the input feature is composed of word embedding representation and domain embedding representation;
a third stage of learning domain-invariant features: constructing a domain damage objective function based on the adversarial domain classifier; inputting the domain embedding representation of a real domain into the classifier to ensure that a damaged output will always be generated; forcing the word embedding representation of Bidirectional Encoder Representation from Transformers (BERT) to be hidden domain information, and ensuring the domain-invariance of the features of an input text;
wherein the method for meta-knowledge fine-tuning based on domain-invariant features is implemented by a platform, and the platform comprises the following components:
a data loading component configured to obtain training samples of a pre-trained language model, wherein the training samples are labeled text samples that satisfy a supervised learning task;
an automatic compression component configured to automatically compress the pre-trained language model, comprising the pre-trained language model and a meta-knowledge fine-tuning module;
wherein the meta-knowledge fine-tuning module is configured to construct a downstream task network on the pre-trained language model generated by the automatic compression component, fine-tune a downstream task scene by using meta-knowledge of the domain-invariant features, and output a finally fine-tuned compression model; the compression model is output to a designated container for a login user to download, and comparison information about model sizes before and after compression is presented on a page of the output compression model of the platform;
a reasoning component, wherein the login user obtains a pre-trained compression model from the platform, and the user uses the compression model output by the automatic compression component to reason new data of a natural language processing downstream task uploaded by the login user on a data set of an actual scene; and the comparison information about reasoning speeds before and after compression is presented on a page of the compression model reasoning of the platform.
|