| CPC G06N 3/04 (2013.01) [G06F 9/5027 (2013.01); G06F 13/00 (2013.01); G06N 3/063 (2013.01); G06T 1/20 (2013.01)] | 8 Claims |
|
1. A hardware architecture for accelerating an artificial intelligence processor, comprising:
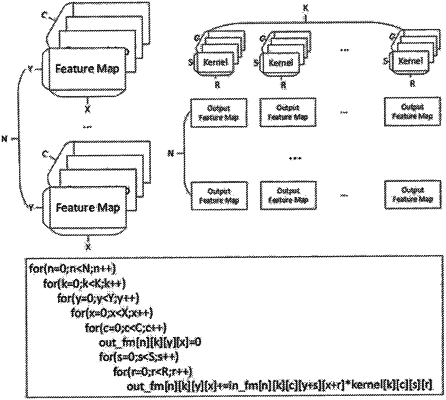
artificial intelligence task is regarded as a 5D tensor in an application-specific integrated circuit (ASIC), and in each dimension, the task is divided into groups, and each group being further divided into a plurality of waves;
a host,
a frontal engine,
a parietal engine,
a renderer engine,
an occipital engine,
a temporal engine, and
a memory, wherein the memory comprises random access memory (RAM);
wherein the frontal engine obtains a 5D tensor from the host and divides the 5D tensor into a plurality of tensors, wherein the parietal engine sends the plurality of tensors to the renderer engine, wherein the renderer engine is configured to execute an input feature renderer and a partial tensor output to the occipital engine, wherein the occipital engine accumulates a partial tensor and executes an output feature renderer to obtain a final tensor sent to the temporal engine, wherein the temporal engine performs data compression and writes the final tensor into the memory.
|