| CPC G06N 3/006 (2013.01) [G06F 18/2155 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01)] | 20 Claims |
|
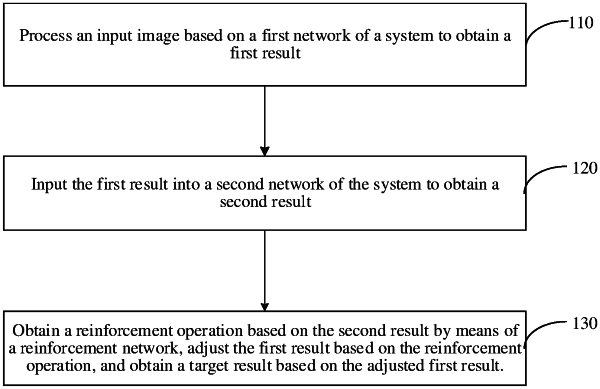
1. A system reinforcement learning method, comprising:
processing an input image based on a first network of a system to obtain a first result;
inputting the first result into a second network of the system to obtain a second result; and
obtaining a reinforcement operation based on the second result by using a reinforcement network, adjusting the first result based on the reinforcement operation by using the reinforcement network, and obtaining a target result by using the second network based on the adjusted first result, which comprises:
obtaining the reinforcement operation by using the reinforcement network based on the second result outputted by the second network, and adjusting the first result based on the reinforcement operation to obtain a first intermediate result;
inputting the first intermediate result into the second network, obtaining the second result based on the first intermediate result, and inputting the second result into the reinforcement network; and
outputting the second result as the target result in response to a preset condition being met,
wherein the reinforcement operation comprises at least one adjustment action; and
the obtaining the reinforcement operation by using the reinforcement network based on the second result outputted by the second network, and adjusting the first result based on the reinforcement operation to obtain the first intermediate result comprises:
obtaining at least one adjustment action probability based on the second result by using the reinforcement network, and determining the at least one adjustment action based on the at least one adjustment action probability; and
adjusting the first result based on the at least one adjustment action to obtain the first intermediate result.
|