| CPC G06F 40/284 (2020.01) [G06F 21/577 (2013.01); G06F 40/253 (2020.01); G06F 40/30 (2020.01); G06N 20/00 (2019.01); G06F 2221/033 (2013.01)] | 20 Claims |
|
1. A method for determining the robustness of a natural language processing (NLP) model, the method comprising:
identifying, by processing circuitry, at least one potential trigger token by searching an embedding space of a first NLP model based on a loss function for the first NLP model;
obtaining, by the processing circuitry, at least one instance of test data, the at least one instance of test data (a) comprising one or more words, (b) having a syntax, and (c) having a semantic meaning;
based on the at least one potential trigger token and the at least one instance of test data, determining, by the processing circuitry, at least one modification trigger;
determining, by the processing circuitry, one or more modifying tokens corresponding to the at least one modification trigger;
generating, by the processing circuitry, one or more instances of modified test data wherein each modified instances of test data is generated by:
identifying a location of the at least one modification trigger within the at least one instance of test data, and
generating a new instance of modified test data which is the instance of test data modified at the location of the at least one modification trigger by one of the one or more modifying tokens corresponding to the at least one modification trigger;
providing, by the processing circuitry, the at least one instance of test data and the one or more instances of modified test data as input to the first NLP model;
for each of the at least one instance of test data and the one or more instances of modified test data provided as input to the first NLP model, obtaining, by the processing circuitry, a corresponding output from the first NLP model;
determining, by the processing circuitry and using a machine learning model, which of the one or more instances of modified test data provided as input to the first NLP model correspond to an output that does not satisfy a similarity criteria with respect to the output corresponding to the corresponding instance of test data;
determining, by the processing circuitry, robustness information for the first NLP model based on which of the one or more instances of modified test data correspond to an output that does not satisfy a similarity criteria with respect to the output corresponding to the corresponding instance of test data; and
causing, by the processing circuitry, the robustness information for the first NLP model to be provided,
wherein the method further comprises:
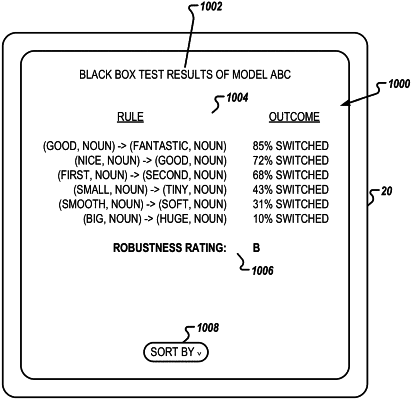
determining one or more output changing modification rules based on which of the one or more instances of modified test data correspond to an output that does not satisfy a similarity criteria with respect to the output corresponding to the corresponding instance of test data;
generating a set of instances of modified test data based on a set of instances of test data and the one or more output changing modification rules;
providing at least a portion of the set of instances of modified test data and the set of instances of test data to a second NLP model;
for each instance of the at least a portion of the set of instances of modified test data and the set of instances of test data provided to the second NLP model, obtaining a corresponding second NLP model output from the second NLP model;
based on the second NLP model output for each of the instances of the at least a portion of the set of instances of modified test data and the set of instances of test data provided to the second NLP model, determining robustness information for the second NLP model; and
causing the robustness information for the second NLP model to be provided.
|