| CPC G06F 40/279 (2020.01) [G06N 3/08 (2013.01)] | 20 Claims |
|
1. A computer implemented method to assign a similarity value to a comparison document, comprising:
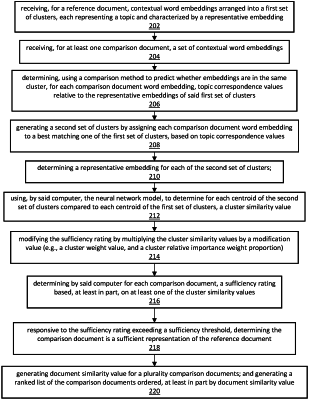
receiving by said computer, for a reference document, contextual word embeddings arranged into a first set of clusters, each representing a topic and characterized by a representative embedding;
receiving by said computer, for at least one comparison document, a set of contextual word embeddings;
determining, by said computer, using a neural network model classifier trained to predict whether embeddings are in a same cluster, for each comparison document contextual word embedding, topic correspondence values relative to the representative embeddings of said first set of clusters;
generating, by said computer, a second set of clusters by assigning each comparison document contextual word embedding to a best matching one of the first set of clusters, according to the topic correspondence values;
determining by said computer, a representative embedding for each of the second set of clusters;
using, by said computer, a comparison method, to determine for each centroid of the second set of clusters compared to each centroid of the first set of clusters, a cluster similarity value; and
determining, by said computer for each comparison document, a document similarity value based, at least in part, on at least one of the cluster similarity values.
|